There are a lot of problems that can occur in SEO, and it can be super time consuming to complete a full audit - especially if you’re simply looking to identify if there is an opportunity to improve organic visibility on your site. Sometimes you just need to find quick wins, quickly, and you may not always have access to a huge tool suite. The tips below can be used to quickly identify if there are major roadblocks separating your website from success using just your browser. Reviewing these checkpoints should allow you to very quickly identify if there are severe problems that justify an investment in a technical SEO audit.
Table of Contents
1) Missing or poorly written Robots.txt
3) Index bloat
6) Broken links
8) Missing or error prone schema markup
10) Cloaking/Major differences between initial HTML and fully rendered site
How to Identify Common SEO Issues With Your Browser
it Matters:
The robots.txt file is one of the first places that search engines check when they crawl a site, which makes it very valuable to not just have a robots.txt file, but to ensure that the directives listed in it (basically, the rules that say what big G should or shouldn’t look at) are accurate and do not block critical aspects of your site. We also want to be sure that we’re declaring our XML sitemap here, as it makes it easier for search engines to find this repository of key pages on our site.
Tool to Use:
Your Browser
How to Check:
The robots.txt file for every site is typically found at www.example.com/robots.txt. It is a plain text file that contains regex driven rules for crawlers. In other words, add /robots.txt to your homepage and you should find the file.
What to Look for:
When we check a robots.txt file, we want to make sure that the following directives are there:
| User-agent: * Allow: / Sitemap: www.example.com/sitemap.xml |
This basically says that every page is allowed to be viewed by any user-agent, and we would then like it to check out our XML sitemap. This example would work pretty well for a basic site that doesn’t have a lot of pages that we don’t want crawled.
What we don’t want to see when we go to the robots.txt on a website is something like this:
| User-agent: * Disallow: / |
This tells search engines that we don’t want them to crawl a single page on our site. This is especially ineffective when our site is already indexed, as it means that Google won’t be able to crawl to see things like our page titles, meta descriptions, etc.
How to Resolve:
It seems like it should be simple -- make sure you’ve got crawl rules set up so that your website can be parsed by search engines. Remarkably though, this gets missed quite often. So, double-check your site’s robots.txt file and ensure that you’re not blocking the whole site from being crawled. Don’t be that guy. Check your robots.txt and make sure crawlers are allowed.
2. Missing XML Sitemap
Why It Matters:
The XML sitemap is the second place that search engines typically arrive when they crawl a site. It’s a collection of every page on the site that we want to serve to search engines. By having an XML sitemap in good condition, we can be sure that search engines can find key pages on our site.
Tools to Use:
Your Browser
How to Check:
If the XML sitemap exists on a site, it’ll be found in likely one of two URLs. Either at www.example.com/sitemap_index.xml or at www.example.com/sitemap.xml. Either URL structure is fine, although Google will likely check /sitemap.xml by default. The first is typically a collection of multiple sitemaps, whereas the second is typically just one. This can also occur as, for instance, www.example.com/post_sitemap.xml, and other variations. You can (and should) also check your robots.txt file (mentioned above) to ensure that your XML sitemap is called out there.
What to Look For:
At this stage, we’re really just checking to make sure that the XML sitemap is there, which we can do by just going to that page. The next step will be to check the status of all of the URLs in that XML sitemap, as search engines have a very low tolerance for ‘dirt’, or non-200 status URLs, in the sitemap. This can be done with Screaming Frog, or even in G-Sheets, but really, we just want to check that there is an XML sitemap or not for right now. So if it’s there and is reported as properly read in Google Search Console then you are good to go!
How to Resolve:
If you are missing an XML sitemap, use this guide to create one! Alternatively, there are many options online that can create an XML sitemap for you. If your website is based on WordPress there are also a variety of plugins that will generate dynamic XML sitemaps, which will update automatically when new content is posted.
3. Index Bloat
 Why It Matters:
Why It Matters:
Index bloat occurs when search engines begin to index pages that shouldn’t be indexed. This can then lead to confusion for search engines when there are, in the case of an e-commerce site, thousands of close variants of a single product category. When there are that many near-identical pages it means that search engines can struggle to identify what page is the most relevant to searchers, and may serve up irrelevant results instead of the ideal page. Index bloat can also lead to a ton of duplicate content problems - especially if the indexed pages don’t have particularly unique information to distinguish them apart from each other. Typically, when there is index bloat on a site, there are also some crawl budget issues that could be resolved, as these two aspects go hand in hand. Basically, because we have poor crawl directives, search engines are accessing pages we’d prefer that they didn’t, and choosing to index them. This may mean that search engines are also having a tough time finding the pages that actually matter to users as a result of not being directed away from pages that add little value to the site.
Tools to Use:
Your Browser
Google Search Console
How to Check:
Okay, this is a bit tough to diagnose and resolve with just your browser, but it’s not impossible. First, we’ll want to run a site search (site:example.com). To get an idea of how many pages have been indexed by Google. We’ll then hop into Google Search Console, go to submitted sitemaps, and see how many URLs were discovered there. We will also want to take a look at GSC to identify how many pages received organic traffic over a 12 month period. If there is a substantial mismatch here (see image above), then it’s likely you are affected by index bloat.
What to Look For:
After completing the steps above, you should have a decent understanding of how many pages are in Google’s index, and how many pages you’ve actually submitted to search engines (through the XML sitemap). It’s not unusual for there to be more results in the index than in GSC or your XML sitemap, but if that ratio is enormous -- like 20,000+ plus pages for a 500 page site -- then you’ve likely got some indexing issues. In fact, it should be expected that there won’t be a 1:1:1 ratio of pages, but there shouldn’t be dramatically different numbers of affected pages here.
How to Resolve:
The resolution to index bloat is a bit trickier, as it is extremely helpful to throw the site into Screaming Frog and get an idea of how many pages can be found in a crawl. But, what we can also do, is extend our Google SERP to show 100 results per page, then we can use a plugin like Link Grabber to grab every URL on each results page. We’ll then filter to see only the domain we want, and can start to get an idea of what type of pages are flooding the index. In many instances, this is as a result of parameterized pages, category or tag pages, and subdomains. Generally anything with a /?stuff& is a low quality page that we’d prefer to prioritize elsewhere.
Now that we’ve got a list of URLs, the next step is to use the Inspect URL tool in GSC to identify how the page was discovered (XML sitemap or crawl?) and create a plan of attack on how to remove these pages from the index -- whether through creating robust robots.txt directives, implementing nofollow or noindex tags, or even by identifying pages to add a 410 header status to so that the page will eventually drop from the index. There are a lot of possible steps forward, so it’s best to get an idea of how extensive this problem is, and then begin to develop a strategy to resolve this issue.
4. Multiple or Missing Google Analytics Tags
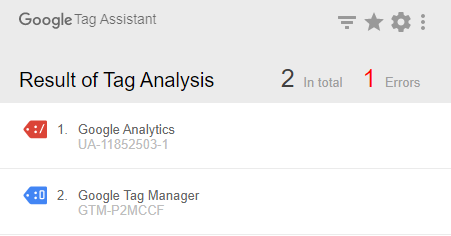
Why It Matters: This would typically be a problem for an Analytics Consultant to solve, but it’s also super simple to identify. Basically, we want to ensure there is one instance of the Google Analytics tracking code on our site. It’s fine if there are different GA tags, or even different tags for different views, but there should never be multiples of the same tag on a page, as it may contribute to double counting in Analytics.
Tools to Use:
Tag Assistant Plugin for Chrome
How to Check:
First, download the Tag Assistant Plugin for Chrome. Then, you’ll go to the home page or any other page that you wish to investigate. Select “Record”, then refresh the page, and review what Tag Assistant finds.
What to Look For:
What we want to look for here is multiples of the same tag. If there are tags submitted in different ways, for instance 1 through Google Tag Manager and another through the raw HTML, then that’s a problem. At the same time, if we have multiple instances of the same tracking code on the page, this is also a problem.
How to Resolve:
First, determine how you want to ensure your tracking information is deployed on the site. Do you want it hardcoded? Or would you prefer Google Tag Manager? From there, it’s a matter of cleaning up irrelevant scripts on the site and ensuring there is just one. While you can’t exactly resolve this with your browser entirely, but this can be very quickly accomplished using Screaming Frog.
5. Unoptimized 404 Pages
Why It Matters:
OK, straight up, there is only one correct way to configure a 404 page. When you go to a page that doesn’t exist then you should see an error or 404 page. This should then provide some links to the top pages on the site, as well as a search bar, and typically messaging saying “sorry, your page can’t be found”. This page should also send a 404 header status to your browser, indicating that it truly doesn’t exist. Pretty much any other variation of this implementation is fundamentally wrong and can lead to some confusing situations for search engines. So, make sure your 404 page is properly configured.
Tools to Use:
Your Browser
How to Check:
So, to find out if this is a problem, I typically go to a site, then create a URL (www.example.com/your-full-name/) and use the Ayima Redirect Plugin to see what happens. If the page shows a 404 status, then we’re all good and there is no issue. If we get redirected, then we’ve got a problem. If we see a 200 status header on a page that definitely shouldn’t exist, then that’s a problem.
What to Look For:
One common example of how this gets messed up is when a website 301 redirects users from a page that doesn’t exist, to a specific 404 page (think about being redirected from www.example.com/your-full-name/ to www.example.com/page-not-found/) that sends off a 200 header status to your browser. The problem is that a 404 page can signal to search engines that a resource should be removed from the index, but by redirecting a page that no longer exists to a 404 page, then we’re not ending that same signal. Potentially, by not having a NoIndex tag on this page, then there’s a good chance that your 200 status 404 page will actually become indexed, which is super preventable by just setting this up the right way in the first place.
How to Resolve:
Long story short, if a page does not exist, it should show a 404 status with a templated design that helps users out. Any other alternative to this is fundamentally incorrect. Not just from an SEO standpoint, but in terms of how web pages should be built.
6. Broken Links
Why It Matters:
Broken links are a problem for a number of reasons, but mainly, it’s just a nuisance for users and search engines. No one wants to be linked to a page that doesn’t exist (doubly so if #5 is an issue on the site). So it’s important to make sure that if you have a link, it goes to a 200 status page.
Tools to Use:
How to Check:
Now, admittedly, this isn’t exactly the fastest way to find broken links, rather, this is a great way to spot check pages. First, install Broken Link Checker or any other broken link checker plugin. Pick a page, any page. You’ll then run the plugin and look to see what it finds.
What to Look For:
To be honest, your plugin is going to do a majority of the work. Just click it, let it run, and see what links it finds.
How to Resolve:
If you’ve got a broken link on your page then update it to the correct destination page. No one wants to be linked to a 404, so, fix that. At the same time, if you’re sending someone through a redirect loop, then your plugin will likely also find that. So fix that link too.
7. Multiple Access Points
Why It Matters:
Okay, again, there is only one correct way to do this. Every site should only have one point of access. HTTP should redirect to HTTPS (if enabled). www should redirect to non-www, and vice versa. Trailing slash should redirect to non-trailing, etc. Uppercase (sometimes) should redirect to lowercase. Basically, there needs to ONLY be one accessible version of the url, and the alternative needs to redirect to the preferred version.
The danger here is that if the non-preferred version of the page is linked to by ANYTHING (internal or external links) then there is a decent chance that search engines see this as a second page. We need to avoid that, as it’s a quality signal, and also why would we willingly create duplicate content? Moreover, if someone is linking to http://[example website].com and we're not redirecting that page then we're losing out on link equity. That's to say, http://[example website].com may have a ton of referring domains pointed to it, but this doesn't help the URL we want https:/[example website].com/ to grow in authority unless we're 301 redirecting these pages.
So to conclude…
ONE ACCESS POINT.
THAT'S IT.
NO MORE.
NO LESS.
Anyways...
Tools to Use:
How to Check:
You can test this on your site by installing the Ayima Redirect Plugin (this tool gets a lot of use from me) trying each of the alternatives below on your site:
| HTTP vs HTTPS | Trailing Slash | www vs no-www | Lowercase vs Uppercase |
| https://www.[example website].com/ | https://www.[example website].com/ | https://www.[example website].com/ | https://www.[EXAMPLE WEBSITE].com/ |
| http://www.[example website].com/ | https://www.[example website].com | https://[example website].com/ | https://www.[example website].com/ |
*for what it’s worth, I’ve only included HTTPS examples. You’ll want to check the same thing for HTTP pages.
What to Look For:
If every iteration of your homepage is redirecting to the proper destination page, then you’re fine and there’s not a lot to worry about. If you are NOT being redirected to the preferred protocol then...well, ya got an issue.
How to Resolve:
I’m not going to get too prescriptive here because, like most things in SEO, it depends.
8. Missing or Error Riddled Schema Markup
Why It Matters:
There is just some schema that every website should have. You’re a local business? Get LocalBusiness. You’re an organization? Add it Organization. Schema helps build relationships between entities, such as a service to a webpage, to a service area, to a business, and even to specific folks. You need it, and it needs to be accurate.
Tools to Use:
Your Browser
The Structured Data Testing Tool
How to Check:
So start by going here: The Structured Data Testing Tool, and drop your site in.If you don't see anything, it actually could be as a result of a non-ideal implementation. It's better to have your schema in the raw HTML, but sometimes folks use Google Tag Manager as a work around. That's just fine -- it'll be read, but it won't be picked up in the SDTT. So pop your site into here: The Mobile Friendly Testing Tool, grab the code it spits out, then drop that back into the SDTT. This is the rendered DOM - basically what Google sees.
What to Look For:
Once we’ve run our site through those tools, we’re basically just looking for whether or not there is schema being triggered on the site or not. If you’re not seeing any schema still, or if your schema is riddled with errors, then you’ve got a problem. One note is that Google will ignore warnings, but errors represent problems.
How to Resolve:
If you don’t have schema, then write some! If you do, but it’s triggering a ton of errors then you should definitely work those out. One pro tip is that you can’t use curly quotes ( “ ) in markup, which is a pretty common culprit of schema errors.
9. Presence of Subdomains (That you didn’t know about and are under-optimized)
Why It Matters:
Believe it or not, subdomains are treated as entirely separate domains by Google. This means they need their own XML sitemaps, their own Robots.txt directives, and even their own GSC account to ensure you’re staying on top of those sites. Unfortunately, it’s not always easy to tell if you’re working on a site with multiple subdomains or not.
Tools to Use:
Your Browser
How to Check:
There are a handful of methods you can use to identify subdomains on a site. My go to is to use search operators, of which there are billions. Dr.Pete from Moz even wrote 5,344 words to show you how many search operators there are. Personally, I don’t think you as an SEO need to know more than 17 search operators.
Specifically what we want to use for this task is this guy:

What this does is searches for anything that contains yourdomain., but it excludes the .com. This means you may even find TLDs you didn’t know about as well. In reality though, the ONLY real reliable method of finding other subdomains, in my opinion, is Screaming Frog, but I recently found this tool: https://findsubdomains.com/ which is pretty solid. Definitely a starting place. Just pop your site in there, if it finds some subdomains, then you'll do a site:search to see exactly how big that subdomain is.
What to Look For:
Subdomains can help contribute to index bloat as well as duplicate content issues, and a variety of other problems. Once we’ve identified the existence of one, we then want to ensure it has its own XML sitemap and Robots.txt.
How to Resolve:
Subdomains aren’t inherently an issue on a site, so there isn’t an inherent resolution here. Subdomains that are under optimized though? Yeah they could be problematic. For now, we’re only focusing on resolving crawl issues here by ensuring they’ve got their own robots.txt and xml sitemap files, but there are a number of issues that subdomains could introduce. In general, I would always recommend using a subfolder as opposed to a subdomain to host content.
10. Cloaking/Major Differences between Initial HTML & Fully Rendered Site
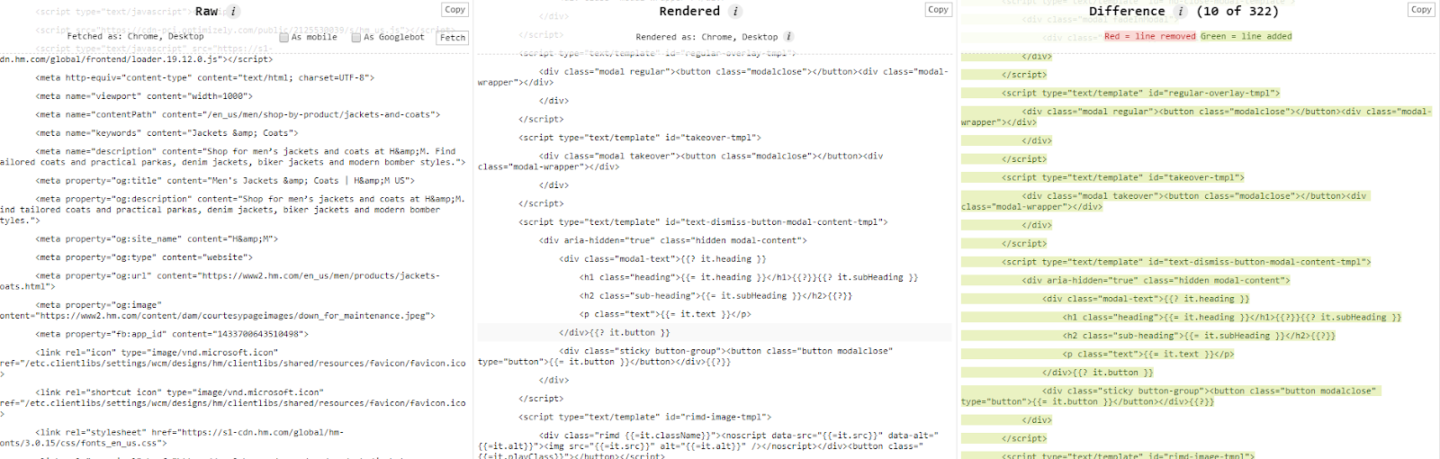
Why It Matters:
SEO, at its core, comes down to a Crawl -> Render -> Index -> Rank model. There are a lot more steps there, but we're keeping it brief. One issue with the web these days is the overwhelming use of JavaScript to make a website come to life, and one thing Google does is review how different your raw submitted HTML is vs the rendered DOM. This is where we start to get into the first & second wave of rendering, another tricky topic that will potentially become irrelevant. Basically they're just making sure you're not cloaking anything and that users are seeing the same page Google does.
Tools to Use:
Your Browser
How to Check:
This is pretty easy to test. We can use things like GSC render, but if we want to see the actual difference between the two in terms of code, we can use this super gnarly plugin - View Rendered Source to get an idea of what's changing.
What to Look For:
If there are ENORMOUS changes then this could be a problem, and could require your site to go through the second wave of rendering before it's indexed.
How to Resolve:
The resolution here is pretty simple sounding, but the work behind it is pretty intense. Basically, make sure that you’re sending as much of the core of the site in the initial HTML load as you possibly can. If that’s not feasible, then I’d highly recommend reviewing Jamie Alberico’s introduction to rendering to give you a running start. From there,
And that’s it, y’all.
This post is really not meant to be fully diagnostic and descriptive of some pretty heavy SEO issues. You should think of it as some quick checks, with some directional information to resolve. There are still a ton of other issues that could be occurring, and honestly, some of these methods are not remotely the fast way to identify or resolve issues on your site. That said, if you’re trying to identify how much opportunity there is to improve on a site, then you should be able to run through this in 10-15 minutes. Your resolution though? Well, that’s going to take a lot longer. Feel free to contact us to resolve your technical SEO issues.
What other common issues can you find with just your browser? Let me know & reach out at @TheWarySEO
Sign up for our newsletter for more posts like this delivered straight to your inbox:


.png)