When I’m working on an analysis I like having more data than I probably need in front of me. Like, ALL the data. That’s why I like scraping stuff.
I’ve found tons of uses for using custom extraction in Screaming Frog or scraping data with tools like Data Miner, Outwit, or Python - collecting skus or product numbers from pages while running a crawl, pulling local SEO data, scraping communities or forums for user questions, or even grabbing open graph tags or schema.
In this guide, you’ll learn how using Xpaths can help you extract data to build your analysis. Looking for something specific or want to skip to our Xpath cheat sheet, jump to a specific section below:
- What is Xpath?
- How to Use Xpaths
- How to Find Xpaths
- How to Use Screaming Frog's Custom Extraction With XPath's
- How to Use Xpaths in DataMiner
- Xpath Cheat Sheet
- Basic Xpaths
- Xpath for SEO
- Open Graph Tags & Twitter Cards
- Xpath for YouTube
- Sites You Shouldn't Scrape
What is Xpath?
Xpath is a syntax for selecting nodes in XML (Extensible Markup Language) - it can be used to locate elements from content. XPath expressions can be used in HTML, JavaScript, Java, PHP, Python, C, C++, and other languages - making them a versatile tool for scraping data.
How to Use Xpaths
When using XPaths in scraping you can pull important data to help fuel an analysis. Some great examples of using XPaths include:
- Scraping product skus while crawling an eCommerce site with Screaming Frog to match products to landing pages
- Pulling engagement metrics like comments, likes, or dislikes from a competitor’s YouTube videos
- Matching post or update dates on blog posts to landing page URLs
How to Find Xpaths
I like using Chrome’s Inspect Tool to find XPaths. There’s usually a little bit of trial and error when finding the right XPath on a new site - because the structure of a website can vary - elements can have different classes and IDs. There are also plenty of tools and extensions for XPaths out in the wild - but Chrome’s inspect is already built-in and works pretty well.
To find an XPath in Chrome, you can either hit F12 or right-click on the body of the page and select “Inspect” in the menu - this should open up Chrome’s Developer Tools on the Elements tab. You can right click an element and select Copy > Copy Xpath.
To validate your XPath, hit ctrl + f to open the “Find by string, selector, or Xpath” finder. If your XPath selects everything that you want to scrape from the page then you’re good to go! If not, then you have some fiddling around to do. Usually when using Chrome’s Inspector tool you’ll find that the result may be too specific - like if you wanted to select all H3s but you were given the XPath for a specific H3.
How to Use Screaming Frog’s Custom Extraction with Xpaths
Screaming Frog’s Custom Extraction tool allows for extraction using CSSPath, Xpath, or RegEx.
There are some limitations with Screaming Frog - it cannot handle complex navigation or scrolling - if a page contains elements that are hidden unless a user clicks “Load More” or scrolls to load - Screaming Frog won’t scrape that data.
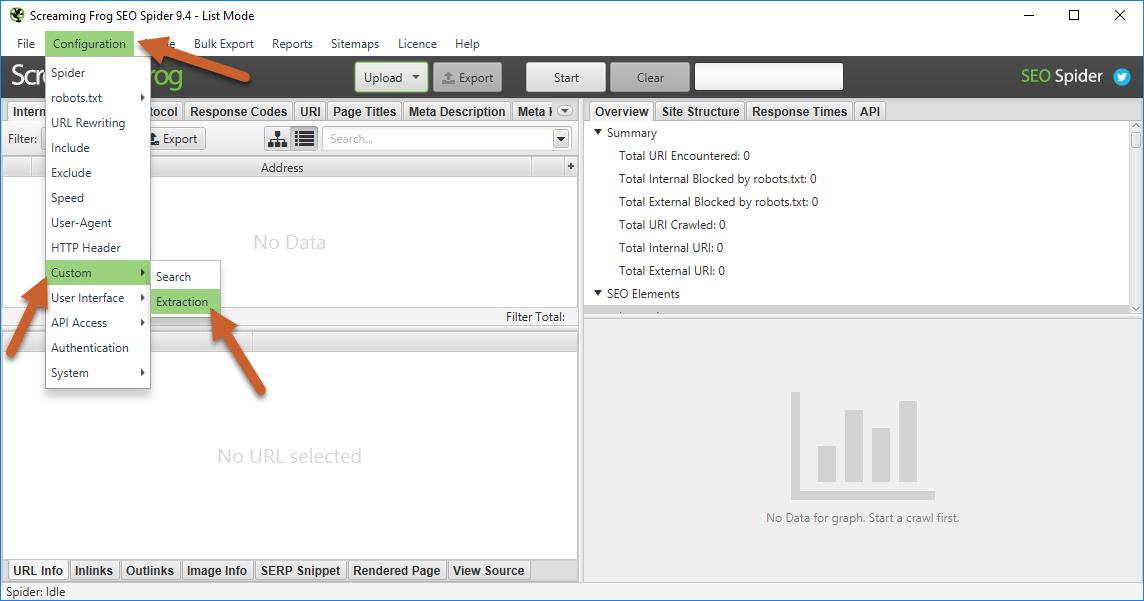
- From the top menu navigation, select Configuration > Custom > Extraction
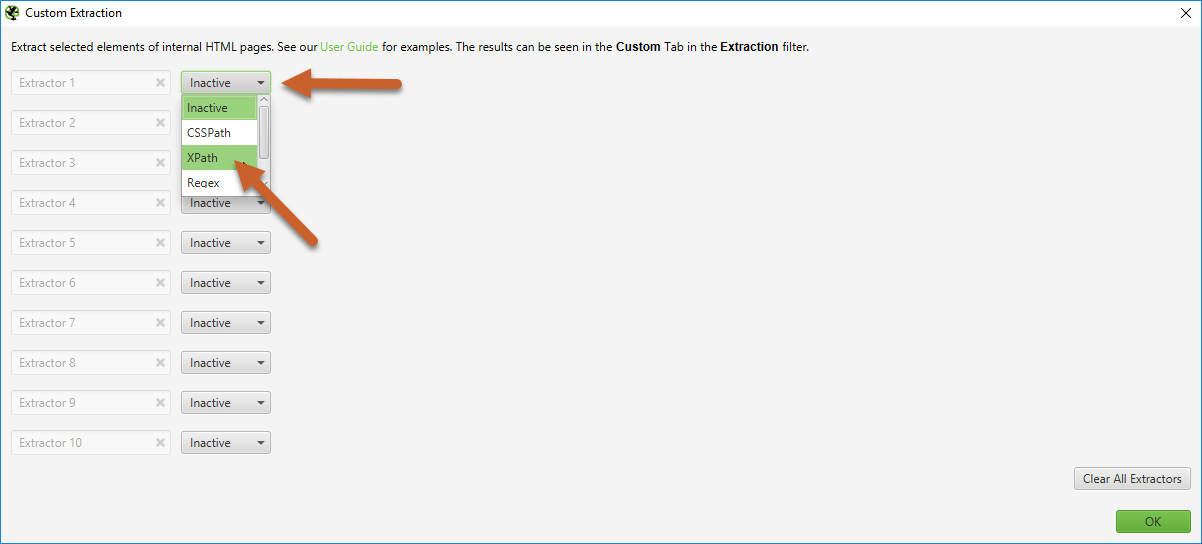
2. Change one of the extractors from “Inactive” to “XPath”
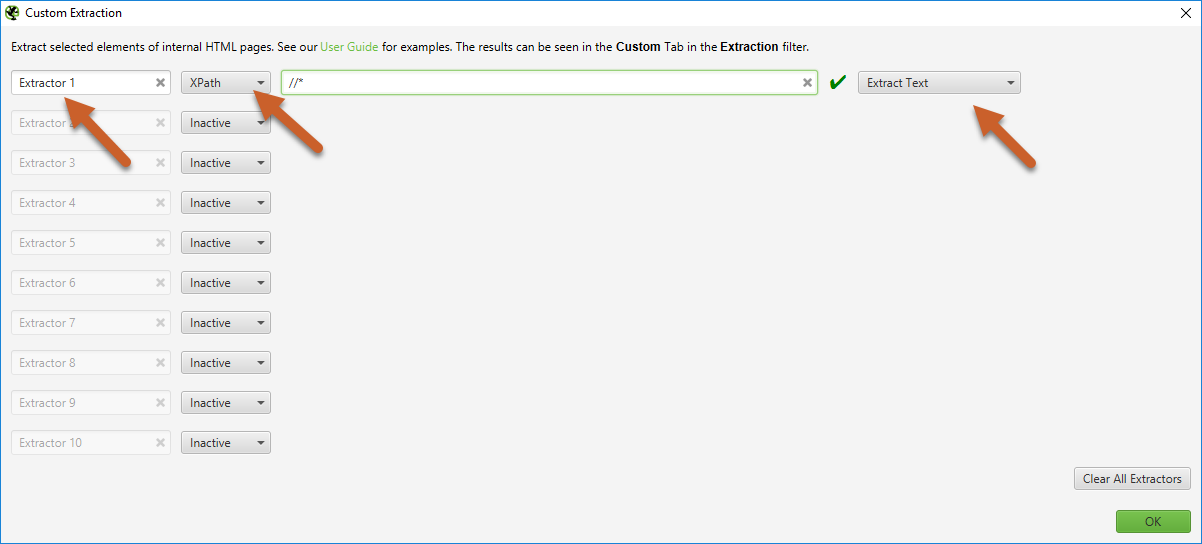
3. Update title to a relevant description (optional), add your XPath into the input, and set the output to one of the following options: Extract Inner HTML, Extract HTML Element, Extract Text, or Function Value.
Screaming Frog includes a green checkmark or red X to the right of the input field - this validates whether the syntax is valid - if you see a red X you will probably need to adjust your syntax.
How to Use Xpaths in DataMiner
Data Miner is another user-friendly tool for basic web scraping - it can automatically click on elements on the page (like “next” or “previous”) or scroll down before scraping the data from that page. It also has a really easy selection functionality for JQuery selection that makes it a great tool for learning how to scrape data.
Xpath Cheat Sheet
There are plenty of XPaths you can use for different tools - in this Xpath cheat sheet, I’ll focus on both basic and site-specific XPaths used in Screaming Frog’s custom extraction tool and Data Miner for this post.
Basic Xpaths
Because the structure of a website can vary - elements can have different classes and IDs, however there are usually some basic XPaths you can scrape that account for most site formatting.
ELEMENT |
XPATH FOR SCREAMING FROG |
EXTRACTION |
| Any element |
//* |
Extract Text |
| Any <p> element |
//p |
Extract Text |
| Any <div> element |
//div | Extract Text |
| Any element with class “example” |
//*[@class=’example’] | Extract Text |
| The whole webpage |
/html | Extract Inner HTML |
| All webpage body |
/html/body | Extract Inner HTML |
| All text |
//text() |
Extract Text |
| All links |
//@href | Extract Text |
| Links with specific anchor text “example” |
//a[contains(., ‘example’)]/@href | Extract Text |
| Email Addresses |
//a[starts-with(@href, 'mailto')] | Extract Text |
Xpath for SEO
Screaming Frog’s spider already includes titles, meta descriptions, H1s, and H2s - but we can also pull more SEO-specific elements like H3s-H6s, hreflang values, or schema markup.
ELEMENT |
XPATH |
EXTRACTION |
| H3 |
//h3 |
Extract Text |
| H3 with specific text “example” |
//h3[contains(text(), "example")] | Extract Text |
| Count of H3s |
count(//h3) | Function |
| Full hreflang (link + value) |
//*[@hreflang] |
Extract Text |
| Hreflang values |
//*[@hreflang]/@hreflang |
Extract Text |
| Types of Schema |
//*[@itemtype]/@itemtype | Extract Text |
| Schema itemprop rules |
//*[@itemprop]/@itemprop | Extract Text |
Open Graph Tags & Twitter Cards
ELEMENT |
XPATH |
EXTRACTION |
| Open Graph Title |
//meta[starts-with(@property, 'og:title')]/@content |
Extract Text |
| Open Graph Description |
//meta[starts-with(@property, 'og:description')]/@content |
Extract Text |
| Open Graph Type |
//meta[starts-with(@property, 'og:type')]/@content | Extract Text |
| Open Graph Site Name |
//meta[starts-with(@property, 'og:site_name')]/@content | Extract Text |
| Open Graph Image |
//meta[starts-with(@property, 'og:image')]/@content | Extract Text |
| Open Graph URL |
//meta[starts-with(@property, 'og:url')]/@content | Extract Text |
| Facebook Page ID |
//meta[starts-with(@property, 'fb:page_id')]/@content | Extract Text |
| Facebook Admins |
//meta[starts-with(@property, 'fb:admins')]/@content |
Extract Text |
| Twitter Title |
//meta[starts-with(@property, 'twitter:title')]/@content | Extract Text |
| Twitter Description |
//meta[starts-with(@property, 'twitter:description')]/@content | Extract Text |
| Twitter Account |
//meta[starts-with(@property, 'twitter:account_id')]/@content | Extract Text |
| Twitter Card |
//meta[starts-with(@property, 'twitter:card')]/@content | Extract Text |
| Twitter Image |
//meta[starts-with(@property, 'twitter:image:src')]/@content | Extract Text |
| Twitter Creator |
//meta[starts-with(@property, 'twitter:creator')]/@content | Extract Text |
Xpath for YouTube
The below XPaths scrape the video titles and URLs from the videos page (https://www.youtube.com/user/[username]/videos) - this will allow you to gather a full inventory of a YouTube channel’s videos.
ELEMENT(VIDEOS PAGE) |
XPATH |
EXTRACTION |
| Video Title |
//h3/a |
Extract Text |
| Video URL |
//h3/a/@href |
Extract Text |
Screaming Frog only pulls the first 30 or so videos from a video page - in order to collect an entire content inventory you’ll need to use a scraper that has the functionality to scroll to the end prior to scraping (like Data Miner).
You can also use the Scraper extension for Chrome to scrape all video URLs after scrolling to the bottom of the page, then right-clicking on a video title and selecting “Scrape similar”.
Once you’ve compiled your list of YouTube video URLs, you can upload them into Screaming Frog as a list and use the below Xpaths to pull information for each video.
ELEMENT (YOUTUBE VIDEO URLS) |
XPATH |
EXTRACTION |
| User Name |
(//*[contains(@class, 'yt-user-info')])[1] |
Extract Text |
| Title |
//title |
Extract Text |
| Publish Date |
//*[(@class='watch-time-text')] |
Extract Text |
| Number of Views |
//*[(@class='watch-view-count')] |
Extract Text |
| Likes |
(//*[contains(@class, 'like-button-renderer-like-button')])[1] |
Extract Text |
| Dislikes |
(//*[contains(@class, 'like-button-renderer-dislike-button')])[1] |
Extract Text |
| Descriptions |
//*[@itemprop='description']/@content |
Extract Text |
Sites You Shouldn’t Scrape
Several websites like Yelp have Terms of Service that don’t allow web scraping. That means that if you’re caught scraping a site like this, your IP address could be blocked from accessing the site.
You can even violate Yelp ToS by running a general Screaming Frog crawl on a Yelp URL - so if you’re ever working on a competitive analysis and plan on running a bulk list of URLs through Screaming Frog - make sure that you remove any Yelp URLs (or URLs from sites with similar Terms of Service).
The number one rule of web scraping is - be nice. If you start using more advanced methods of crawling, throttle your speed so you aren’t slamming the site’s server.
We hope this guide and XPath cheat sheet will help you use Xpaths and scraping for your research and analysis. For more articles and tips and tricks, sign up for the Seer newsletter!


.png)
