Wondering why your page isn't showing up in search results?
There are a plethora of reasons why you might not be seeing your page among the organic results, but before you spend a ton of time and money trying to fix the problem, start with the most fundamental culprit. You can't find your site; can google find it?
Run through this list of top reasons that Google might not be accessing your page and if you aren’t able to find a fix, post in the comments for Seer/readers to help.
1. Google hasn’t indexed it yet.
Look for a cache. If it was launched in the last 1-2 days and your site isn’t amazon or cnn, it’s reasonable to assume Google hasn’t made their way over to your new page.
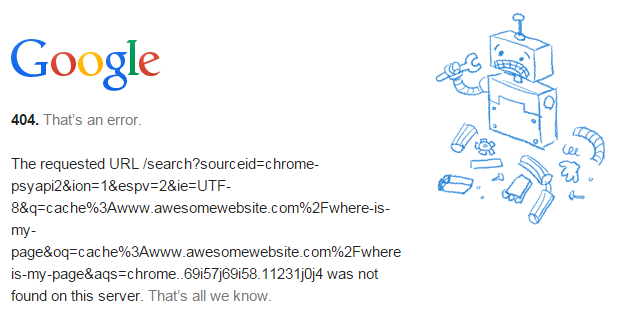
UPDATE: Google's John Mueller said recently that the fastest way to get indexed is by submitting to their Fetch tool within Search Console. Reported by Search Engine Round Table.
2. Google can’t get to it.
Did you link to this page from other pages? Is it in your sitemap? If you answered no to either of those, you may have created an island page.
3. Noindex robots meta
Someone has implemented an instruction to let Google know to not index the page. Remove that little guy and it could fix this issue.
4. Robots.txt exclude.
Could be that page, that folder, or the whole domain. Most common when relaunching your site. If you’re blocking the entire site, the file found at yoursitename.com/robots.txt looks like this:
- User-agent: *
- Disallow: /
5. Googlebot is being blocked by robots.txt.
Very few reasons why you’d have this set up, but while you’re in there seeing if it’s a folder, page, or entire domain being blocked, check if the directive is blocking googlebot.
What are the names of specific user agents in case you want to block them?
- Search Engines:
- Google: Googlebot
- Bing: BingBot
- Tools:
- Ahrefs: AhrefsBot
- Moz: Rogerbot
- Screaming Frog: Screaming Frog SEO Spider
- SEMRush: SemrushBot
- 80legs: 008
A full list of crawler user agent identifiers can be found here.
6. Similar to Google not getting to your page because it’s not linked to, the page may be linked to, but the links are nofollowed.
This, in theory, is another way blocking Google from getting to and then showing your desired page in search results.
7. Canonical is pointing to another page.
The use of rel=canonical is to keep multiple versions of a page from appearing in search and to consolidate the value of all of those page into one the website owner desires to show up. Great uses of the canonical are when you have multiple versions of a homepage, like a non-www version, www, https, as well as a /default page. A canonical tag on all of those pages saying to value the http://www version of the homepage helps that version get all the value.
SO! When a canonical for your blog post or product is pointing to another page, it’s unlikely to appear in search results. If it’s a specific blog post or a specific product page that isn’t showing up, ensure the rel=canonical is referencing that same page (self referencing) or simply remove it if you’re not able to change it.
8. Content is identical to another page or another site...
In this case, Google will likely index the page, but if you’re not seeing organic traffic, it’s probably because the page is in the omitted results.
The easiest way to figure this out is to take a 7-8 word phrase, put it in quotes and search for it. If Google returns many many results, either you have too much duplicated content on your own site OR you’ve taken content from another site (like a manufacturer description) and Google isn’t valuing your page as unique enough.
9. Remove URL in webmaster tools...
It's unlikely, but someone may have requested that page be removed. To find this, login to webmaster tools and go to Google Index – Remove URLs.
There, you’ll be able to see any URL removal request. If it’s showing “No URL removal requests”, then you can check this off as NOT the reason why your page/site isn’t showing up.
Side note – you can remove your entire site by adding a “/” when prompted for the page.
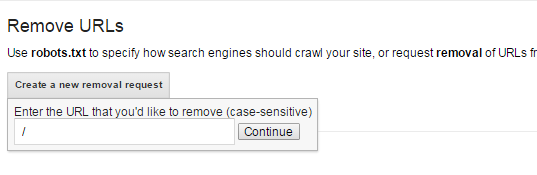
This will effectively remove your entire site from search results for 90 days. With a full site removal request or an individual page request, both expire after 90 days and Google will resume crawling those URLs.
10. If the page has a parameter, it may be marked as crawl No URLs in webmaster tools.
This could further be diagnosed by the page not showing up in Google, but showing up in other engines.
To check, go to the Crawl tab within webmaster tools and in that dropdown select “URL Parameters. If you see any “No URLs”, ensure that the page you’re wanting to be in search results isn’t affected by this instruction.
11. Some type of malware or hijacking.
Google will remove pages. Set up Google Alerts for site:yoursite.com Viagra, Cialis, etc. Within webmaster tools, you should be alerted to this through a message as well as through more specific details within the Security Issues left navigation within Webmaster Tools (Search Console. Google changed the name of Webmaster Tools right in the middle of writing this. Interesting.)
12. Manual action for that page or the entire site.
Should be listed in your Google Search Console. If it’s not, looking at the backlinks to that page to see if there are dozens of links that have no business pointing to your page.
You’ll be hoping to see the image below, showing “No manual webspam actions found.”
13. Ruined pagination...
Maybe you are linking to the page that’s having trouble getting indexed, but it’s linked to from page=2 and you’ve noindexed, nofollowed pagination, canonicalized pagination back to the main category page, or blocked those pages in robots or webmaster tools. If that’s the only way to get to the specific product or blog post, this could be the issue.
Google has a great post to share about 5 common mistakes with rel=canonical where pagination is the first example.
Closing it down, there are times when Google is extremely frustrating and none of the above items resolve your indexation issue. If that is happening, throw your issue into the comments below so the community & Seer people can try and solve it.